So, start with the section that makes the most sense to you and your preferred method of learning. If you need to know everything about everything, feel free to read the whole thing -- but if you are really that type of person, you have perused the source code and will therefore never need this document anyway. ;-)
Splitting the update into removal and reclamation phases permits the updater to perform the removal phase immediately, and to defer the reclamation phase until all readers active during the removal phase have completed, either by blocking until they finish or by registering a callback that is invoked after they finish. Only readers that are active during the removal phase need be considered, because any reader starting after the removal phase will be unable to gain a reference to the removed data items, and therefore cannot be disrupted by the reclamation phase.
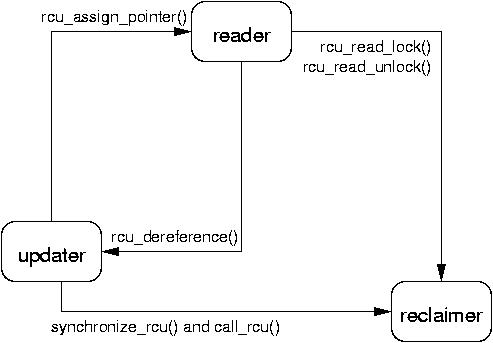
So the typical RCU update sequence goes something like the following:
In the three-step procedure shown above, the updater is performing both the removal and the reclamation step, but it is often helpful for an entirely different thread to do the reclamation, as is in fact the case in the Linux kernel's directory-entry cache (dcache). Even if the same thread performs both the update step (step (a) above) and the reclamation step (step (c) above), it is often helpful to think of them separately. For example, RCU readers and updaters need not communicate at all, but RCU provides implicit low-overhead communication between readers and reclaimers, namely, in step (b) above.
So how the heck can a reclaimer tell when a reader is done, given that readers are not doing any sort of synchronization operations??? Read on to learn about how RCU's API makes this easy.
The five core RCU APIs are described below, the other 18 will be enumerated
later. See the kernel docbook documentation for more info, or look directly
at the function header comments.
rcu_read_lock()
void rcu_read_lock(void);
Used by a reader to inform the reclaimer that the reader is
entering an RCU read-side critical section. It is illegal
to block while in an RCU read-side critical section, though
kernels built with CONFIG_PREEMPT_RCU can preempt RCU read-side
critical sections. Any RCU-protected data structure accessed
during an RCU read-side critical section is guaranteed to remain
unreclaimed for the full duration of that critical section.
Reference counts may be used in conjunction with RCU to maintain
longer-term references to data structures.
rcu_read_unlock()
void rcu_read_unlock(void);
Used by a reader to inform the reclaimer that the reader is
exiting an RCU read-side critical section. Note that RCU
read-side critical sections may be nested and/or overlapping.
synchronize_rcu()
void synchronize_rcu(void);
Marks the end of updater code and the beginning of reclaimer code. It does this by blocking until all pre-existing RCU read-side critical sections on all CPUs have completed. Note that synchronize_rcu() will not necessarily wait for any subsequent RCU read-side critical sections to complete. For example, consider the following sequence of events:
CPU 0 CPU 1 CPU 2 ----------------- ------------------------- --------------- 1. rcu_read_lock() 2. enters synchronize_rcu() 3. rcu_read_lock() 4. rcu_read_unlock() 5. exits synchronize_rcu() 6. rcu_read_unlock()To reiterate, synchronize_rcu() waits only for ongoing RCU read-side critical sections to complete, not necessarily for any that begin after synchronize_rcu() is invoked.
Of course, synchronize_rcu() does not necessarily return immediately after the last pre-existing RCU read-side critical section completes. For one thing, there might well be scheduling delays. For another thing, many RCU implementations process requests in batches in order to improve efficiencies, which can further delay synchronize_rcu().
Since synchronize_rcu() is the API that must figure out when readers are done, its implementation is key to RCU. For RCU to be useful in all but the most read-intensive situations, synchronize_rcu()'s overhead must also be quite small.
The call_rcu() API is a callback form of
synchronize_rcu(),
and is described in more detail in a later section. Instead of
blocking, it registers a function and argument which are invoked
after all ongoing RCU read-side critical sections have completed.
This callback variant is particularly useful in situations where
it is illegal to block.
rcu_assign_pointer()
typeof(p) rcu_assign_pointer(p, typeof(p) v);
Yes, rcu_assign_pointer() is implemented as a macro, though it would be cool to be able to declare a function in this manner. (Compiler experts will no doubt disagree.)
The updater uses this function to assign a new value to an RCU-protected pointer, in order to safely communicate the change in value from the updater to the reader. This function returns the new value, and also executes any memory-barrier instructions required for a given CPU architecture.
Perhaps more important, it serves to document which pointers
are protected by RCU. That said, rcu_assign_pointer() is most
frequently used indirectly, via the _rcu list-manipulation
primitives such as list_add_rcu().
rcu_dereference()
typeof(p) rcu_dereference(p);
Like rcu_assign_pointer(), rcu_dereference() must be implemented as a macro.
The reader uses rcu_dereference() to fetch an RCU-protected pointer, which returns a value that may then be safely dereferenced. Note that rcu_deference() does not actually dereference the pointer, instead, it protects the pointer for later dereferencing. It also executes any needed memory-barrier instructions for a given CPU architecture. Currently, only Alpha needs memory barriers within rcu_dereference() -- on other CPUs, it compiles to nothing, not even a compiler directive.
Common coding practice uses rcu_dereference() to copy an RCU-protected pointer to a local variable, then dereferences this local variable, for example as follows:
p = rcu_dereference(head.next); return p->data;However, in this case, one could just as easily combine these into one statement:
return rcu_dereference(head.next)->data;If you are going to be fetching multiple fields from the RCU-protected structure, using the local variable is of course preferred. Repeated rcu_dereference() calls look ugly and incur unnecessary overhead on Alpha CPUs.
Note that the value returned by rcu_dereference() is valid only within the enclosing RCU read-side critical section. For example, the following is not legal:
rcu_read_lock(); p = rcu_dereference(head.next); rcu_read_unlock(); x = p->address; rcu_read_lock(); y = p->data; rcu_read_unlock();Holding a reference from one RCU read-side critical section to another is just as illegal as holding a reference from one lock-based critical section to another! Similarly, using a reference outside of the critical section in which it was acquired is just as illegal as doing so with normal locking.
As with rcu_assign_pointer(), an important function of rcu_dereference() is to document which pointers are protected by RCU. And, again like rcu_assign_pointer(), rcu_dereference() is typically used indirectly, via the _rcu list-manipulation primitives, such as list_for_each_entry_rcu().
The RCU infrastructure observes the time sequence of rcu_read_lock(), rcu_read_unlock(), synchronize_kernel(), and call_rcu() invocations in order to determine when (1) synchronize_kernel() invocations may return to their callers and (2) call_rcu() callbacks may be invoked. Efficient implementations of the RCU infrastructure make heavy use of batching in order to amortize their overhead over many uses of the corresponding APIs.
There are no fewer than three RCU mechanisms in the Linux kernel; the diagram above shows the first one, which is by far the most commonly used. The rcu_dereference() and rcu_assign_pointer() primitives are used for all four mechanisms, but different defer and protect primitives are used as follows:
Defer Protect
a. synchronize_rcu() rcu_read_lock() / rcu_read_unlock()
call_rcu()
b. call_rcu_bh() rcu_read_lock_bh() / rcu_read_unlock_bh()
c. synchronize_sched() preempt_disable() / preempt_enable()
local_irq_save() / local_irq_restore()
hardirq enter / hardirq exit
NMI enter / NMI exit
d. synchronize_srcu() srcu_read_lock() / srcu_read_unlock()
These four mechanisms are used as follows:
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo *gbl_foo;
/*
* Create a new struct foo that is the same as the one currently
* pointed to by gbl_foo, except that field "a" is replaced
* with "new_a". Points gbl_foo to the new structure, and
* frees up the old structure after a grace period.
*
* Uses rcu_assign_pointer() to ensure that concurrent readers
* see the initialized version of the new structure.
*
* Uses synchronize_rcu() to ensure that any readers that might
* have references to the old structure complete before freeing
* the old structure.
*/
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = gbl_foo;
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
synchronize_rcu();
kfree(old_fp);
}
/*
* Return the value of field "a" of the current gbl_foo
* structure. Use rcu_read_lock() and rcu_read_unlock()
* to ensure that the structure does not get deleted out
* from under us, and use rcu_dereference() to ensure that
* we see the initialized version of the structure (important
* for DEC Alpha and for people reading the code).
*/
int foo_get_a(void)
{
int retval;
rcu_read_lock();
retval = rcu_dereference(gbl_foo)->a;
rcu_read_unlock();
return retval;
}
So, to sum up:
In such cases, one uses call_rcu() rather than synchronize_rcu(). The call_rcu() API is as follows:
void call_rcu(struct rcu_head * head, void (*func)(struct rcu_head *head));This function invokes func(head) after a grace period has elapsed. This invocation might happen from either softirq or process context, so the function is not permitted to block. The foo struct needs to have an rcu_head structure added, perhaps as follows:
struct foo {
int a;
char b;
long c;
struct rcu_head rcu;
};
The foo_update_a() function might then be written as follows:
/*
* Create a new struct foo that is the same as the one currently
* pointed to by gbl_foo, except that field "a" is replaced
* with "new_a". Points gbl_foo to the new structure, and
* frees up the old structure after a grace period.
*
* Uses rcu_assign_pointer() to ensure that concurrent readers
* see the initialized version of the new structure.
*
* Uses call_rcu() to ensure that any readers that might have
* references to the old structure complete before freeing the
* old structure.
*/
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*fp), GFP_KERNEL);
spin_lock(&foo_mutex);
old_fp = gbl_foo;
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp);
spin_unlock(&foo_mutex);
call_rcu(&old_fp->rcu, foo_reclaim);
}
The foo_reclaim() function might appear as follows:
void foo_reclaim(struct rcu_head *rp)
{
struct foo *fp = container_of(rp, struct foo, rcu);
kfree(fp);
}
The container_of() primitive is a macro that, given a pointer into a
struct, the type of the struct, and the pointed-to field within the
struct, returns a pointer to the beginning of the struct.
The use of call_rcu() permits the caller of foo_update_a() to immediately regain control, without needing to worry further about the old version of the newly updated element. It also clearly shows the RCU distinction between updater, namely foo_update_a(), and reclaimer, namely foo_reclaim().
The summary of advice is the same as for the previous section, except that we are now using call_rcu() rather than synchronize_rcu():
http://www.rdrop.com/users/paulmck/RCUfor papers describing the Linux kernel RCU implementation. The OLS'01 and OLS'02 papers are a good introduction, and the dissertation provides more details on the current implementation.
However, it is probably the easiest implementation to relate to, so is a good starting point.
It is extremely simple:
static DEFINE_RWLOCK(rcu_gp_mutex);
void rcu_read_lock(void)
{
read_lock(&rcu_gp_mutex);
}
void rcu_read_unlock(void)
{
read_unlock(&rcu_gp_mutex);
}
void synchronize_rcu(void)
{
write_lock(&rcu_gp_mutex);
write_unlock(&rcu_gp_mutex);
}
[You can ignore rcu_assign_pointer() and rcu_dereference()
without
missing much. But here they are anyway. And whatever you do, don't
forget about them when submitting patches making use of RCU!]
#define rcu_assign_pointer(p, v) ({ \
smp_wmb(); \
(p) = (v); \
})
#define rcu_dereference(p) ({ \
typeof(p) _________p1 = p; \
smp_read_barrier_depends(); \
(_________p1); \
})
The rcu_read_lock() and rcu_read_unlock()
primitive read-acquire
and release a global reader-writer lock. The synchronize_rcu()
primitive write-acquires this same lock, then immediately releases
it. This means that once synchronize_rcu() exits, all RCU read-side
critical sections that were in progress before synchonize_rcu() was
called are guaranteed to have completed -- there is no way that
synchronize_rcu() would have been able to write-acquire the lock
otherwise.
It is possible to nest rcu_read_lock(), since reader-writer locks may be recursively acquired. Note also that rcu_read_lock() is immune from deadlock (an important property of RCU). The reason for this is that the only thing that can block rcu_read_lock() is a synchronize_rcu(). But synchronize_rcu() does not acquire any locks while holding rcu_gp_mutex, so there can be no deadlock cycle.
void rcu_read_lock(void) { }
void rcu_read_unlock(void) { }
void synchronize_rcu(void)
{
int cpu;
for_each_cpu(cpu)
run_on(cpu);
}
Note that rcu_read_lock() and rcu_read_unlock()
do absolutely nothing.
This is the great strength of classic RCU in a non-preemptive kernel:
read-side overhead is precisely zero, at least on non-Alpha CPUs.
And there is absolutely no way that rcu_read_lock() can possibly
participate in a deadlock cycle!
The implementation of synchronize_rcu() simply schedules itself on each CPU in turn. The run_on() primitive can be implemented straightforwardly in terms of the sched_setaffinity() primitive. Of course, a somewhat less "toy" implementation would restore the affinity upon completion rather than just leaving all tasks running on the last CPU, but when I said "toy", I meant toy!
So how the heck is this supposed to work???
Remember that it is illegal to block while in an RCU read-side critical section. Therefore, if a given CPU executes a context switch, we know that it must have completed all preceding RCU read-side critical sections. Once all CPUs have executed a context switch, then all preceding RCU read-side critical sections will have completed.
So, suppose that we remove a data item from its structure and then invoke synchronize_rcu(). Once synchronize_rcu() returns, we are guaranteed that there are no RCU read-side critical sections holding a reference to that data item, so we can safely reclaim it.
@@ -13,15 +14,15 @@
struct list_head *lp;
struct el *p;
- read_lock();
- list_for_each_entry(p, head, lp) {
+ rcu_read_lock();
+ list_for_each_entry_rcu(p, head, lp) {
if (p->key == key) {
*result = p->data;
- read_unlock();
+ rcu_read_unlock();
return 1;
}
}
- read_unlock();
+ rcu_read_unlock();
return 0;
}
@@ -29,15 +30,16 @@
{
struct el *p;
- write_lock(&listmutex);
+ spin_lock(&listmutex);
list_for_each_entry(p, head, lp) {
if (p->key == key) {
- list_del(&p->list);
- write_unlock(&listmutex);
+ list_del_rcu(&p->list);
+ spin_unlock(&listmutex);
+ synchronize_rcu();
kfree(p);
return 1;
}
}
- write_unlock(&listmutex);
+ spin_unlock(&listmutex);
return 0;
}
Or, for those who prefer a side-by-side listing:
1 struct el { 1 struct el {
2 struct list_head list; 2 struct list_head list;
3 long key; 3 long key;
4 spinlock_t mutex; 4 spinlock_t mutex;
5 int data; 5 int data;
6 /* Other data fields */ 6 /* Other data fields */
7 }; 7 };
8 spinlock_t listmutex; 8 spinlock_t listmutex;
9 struct el head; 9 struct el head;
1 int search(long key, int *result) 1 int search(long key, int *result)
2 { 2 {
3 struct list_head *lp; 3 struct list_head *lp;
4 struct el *p; 4 struct el *p;
5 5
6 read_lock(); 6 rcu_read_lock();
7 list_for_each_entry(p, head, lp) { 7 list_for_each_entry_rcu(p, head, lp) {
8 if (p->key == key) { 8 if (p->key == key) {
9 *result = p->data; 9 *result = p->data;
10 read_unlock(); 10 rcu_read_unlock();
11 return 1; 11 return 1;
12 } 12 }
13 } 13 }
14 read_unlock(); 14 rcu_read_unlock();
15 return 0; 15 return 0;
16 } 16 }
1 int delete(long key) 1 int delete(long key)
2 { 2 {
3 struct el *p; 3 struct el *p;
4 4
5 write_lock(&listmutex); 5 spin_lock(&listmutex);
6 list_for_each_entry(p, head, lp) { 6 list_for_each_entry(p, head, lp) {
7 if (p->key == key) { 7 if (p->key == key) {
8 list_del(&p->list); 8 list_del_rcu(&p->list);
9 write_unlock(&listmutex); 9 spin_unlock(&listmutex);
10 synchronize_rcu();
10 kfree(p); 11 kfree(p);
11 return 1; 12 return 1;
12 } 13 }
13 } 14 }
14 write_unlock(&listmutex); 15 spin_unlock(&listmutex);
15 return 0; 16 return 0;
16 } 17 }
Either way, the differences are quite small. Read-side locking moves
to rcu_read_lock() and rcu_read_unlock(),
update-side locking moves from
from a reader-writer lock to a simple spinlock, and a synchronize_rcu()
precedes the kfree().
However, there is one potential catch: the read-side and update-side critical sections can now run concurrently. In many cases, this will not be a problem, but it is necessary to check carefully regardless. For example, if multiple independent list updates must be seen as a single atomic update, converting to RCU will require special care.
Also, the presence of synchronize_rcu() means that the RCU version of delete() can now block. If this is a problem, there is a callback-based mechanism that never blocks, namely call_rcu(), that can be used in place of synchronize_rcu().
Markers for RCU read-side critical sections:
rcu_read_lock rcu_read_unlock rcu_read_lock_bh rcu_read_unlock_bhRCU pointer/list traversal:
rcu_dereference list_for_each_rcu (to be deprecated in favor of list_for_each_entry_rcu) list_for_each_safe_rcu (deprecated, not used) list_for_each_entry_rcu list_for_each_continue_rcu (to be deprecated in favor of new list_for_each_entry_continue_rcu) hlist_for_each_rcu (to be deprecated in favor of hlist_for_each_entry_rcu) hlist_for_each_entry_rcuRCU pointer update:
rcu_assign_pointer list_add_rcu list_add_tail_rcu list_del_rcu list_replace_rcu hlist_del_rcu hlist_add_head_rcuRCU grace period:
synchronize_kernel (deprecated) synchronize_net synchronize_sched synchronize_rcu call_rcu call_rcu_bhSee the comment headers in the source code (or the docbook generated from them) for more information.
One way to avoid this deadlock is to use an approach like that of CONFIG_PREEMPT_RT, where all normal spinlocks become blocking locks, and all irq handlers execute in the context of special tasks. In this case, in step 4 above, the irq handler would block, allowing CPU 1 to release rcu_gp_mutex, avoiding the deadlock.
Even in the absence of deadlock, this RCU implementation allows latency to "bleed" from readers to other readers through synchronize_rcu(). To see this, consider task A in an RCU read-side critical section (thus read-holding rcu_gp_mutex), task B blocked attempting to write-acquire rcu_gp_mutex, and task C blocked in rcu_read_lock() attempting to read_acquire rcu_gp_mutex. Task A's RCU read-side latency is holding up task C, albeit indirectly via task B.
Realtime RCU implementations therefore use a counter-based approach where tasks in RCU read-side critical sections cannot be blocked by tasks executing synchronize_rcu().
One can argue that the overhead of RCU in this case is negative with respect to the single-CPU interrupt-disabling approach. Others might argue that the overhead of RCU is merely zero, and that replacing the positive overhead of the interrupt-disabling scheme with the zero-overhead RCU scheme does not constitute negative overhead.
In real life, of course, things are more complex. But even the theoretical possibility of negative overhead for a synchronization primitive is a bit unexpected. ;-)
Why the apparent inconsistency? Because it is it possible to use priority boosting to keep the RCU grace periods short if need be (for example, if running short of memory). In contrast, if blocking waiting for (say) network reception, there is no way to know what should be boosted. Especially given that the process we need to boost might well be a human being who just went out for a pizza or something. And although a computer-operated cattle prod might arouse serious interest, it might also provoke serious objections. Besides, how does the computer know what pizza parlor the human being went to???
For more information, see http://www.rdrop.com/users/paulmck/RCU and the Wikipedia entry for RCU.